AI in a Cage : The end of the "AI for Everyone" Era

What Happened?
The last 12 months have been something like an unlimited Candy period for us AI enthusiasts. GPT 4x, 5x, Claude Haiku, Sonnet, Opus, Gemini 1,2,2.5 - every 2 weeks we would wait for the Frontier labs to give us a new flavor of AI Candy - we would get a handful and stuff some in our pockets - all for $20/mo.
That era officially ended on June 26, 2026.
With OpenAI's staggered release of its new GPT-5.6 family (spanning the Sol, Terra, and Luna tiers), we are witnessing the first government-gated frontier AI launch in U.S. history. Triggered by a June 2 executive order aimed at benchmarking models with advanced cyber capabilities, OpenAI locked its flagship Sol model behind an approved list of just 20 organizations. While OpenAI publicly voiced its discomfort - stating that a government-led gatekeeping process shouldn't become the long-term industry default—the precedent has been set. Washington has found the software release valve.
The Dual use dilemma
This isn't an isolated incident. We saw the warning shot weeks ago when federal interventions pressured Anthropic into pulling back access to Fable 5 and Mythos 5 over national security and cybersecurity concerns. When the cloud-native keys to frontier intelligence can be turned off or restricted overnight by administrative decree, the entire enterprise and developer ecosystem faces a stark realization: centralized cloud AI is no longer a guaranteed utility.
GPT-5.6 Sol ships with an "ultra" mode designed to deploy coordinated sub-agents to independently decompose and execute highly complex tasks. On specialized benchmarks like Terminal-Bench 2.1 and ExploitBench, it pushes past previous performance ceilings in command-line automation and vulnerability research. The same system that can analyze complex codebases, map exploit paths, and help defenders proactively patch critical zero-days can also scale offensive intrusions, chain exploits together, and operate with an autonomy that terrifies national security officials.
What others are saying
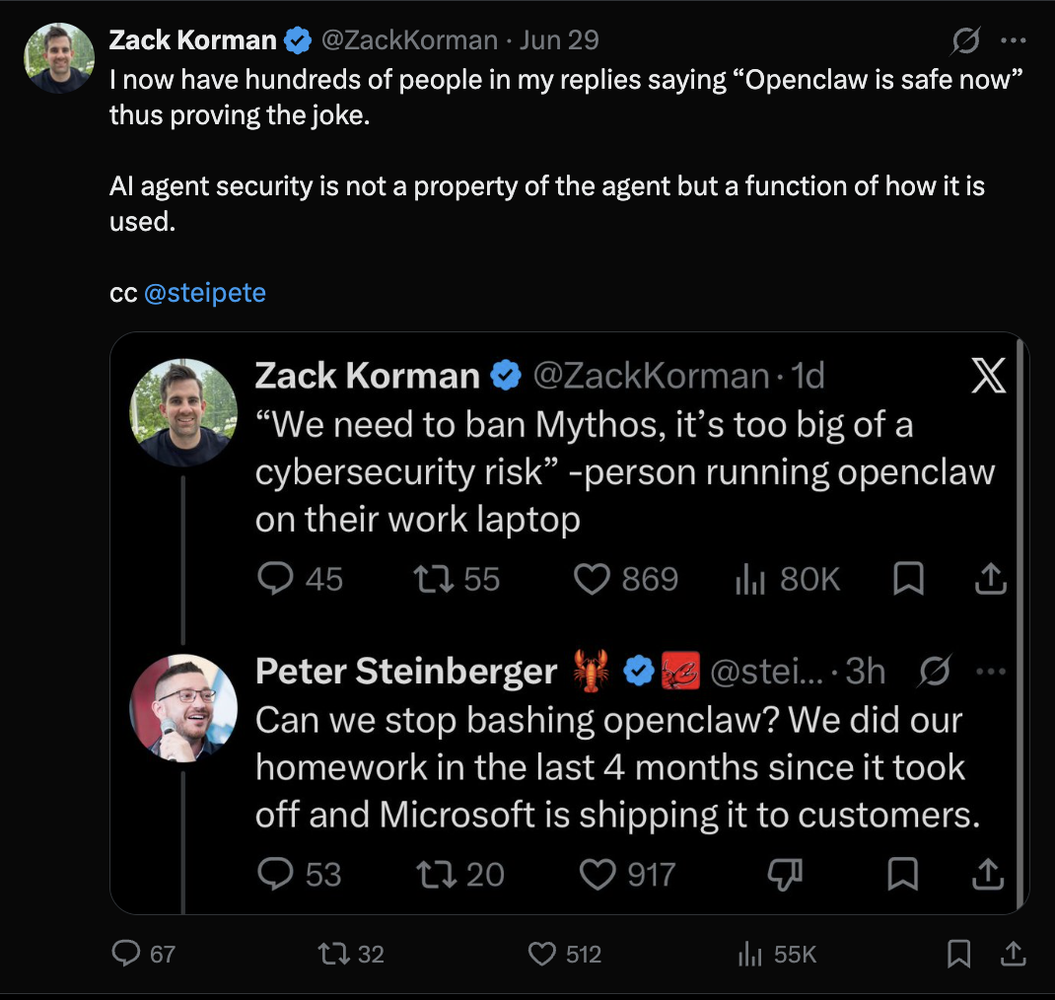
This tension is sparking sharp debates across tech circles. As a recent viral exchange between developers Zack Korman and Peter Steinberger highlighted , there is a deep irony in the current discourse. While the industry fixates on banning or restricting massive, cloud-hosted models like Mythos due to abstract cybersecurity risks, thousands of developers are quietly deploying autonomous open-source agent frameworks like Openclaw directly on their local work laptops. Korman pointed out, the core challenge isn't a criticism of the technology itself - it’s the inherent friction of running autonomous agents with direct access to sensitive corporate and personal data.
The Open Source counter-revolution: Going Local
As centralized frontier models drift toward controlled-access architectures, the gravity of the AI ecosystem is rapidly shifting toward local deployment. If you can't guarantee your access to cloud APIs due to shifting political alignments or regulatory crossfire, building on local, open-source models is no longer just a philosophical choice - it’s a business continuity strategy.
Fortunately, the local open-source alternative has evolved far beyond a hobbyist's sandbox. The decision of how to build out your local infrastructure essentially comes down to a choice between memory scale, raw execution speed, or plug-and-play simplicity:
1. Unified Architecture (e.g., Mac Studio)
The Value: Exceptional for running massive, frontier-level open-source models (like running GLM 5.2 on a single machine).
The Catch: Lower memory bandwidth means these models run at slower speeds.
Best For: Passive, long-horizon intelligence. It’s perfect for background workflows—like executing automated codebase security checks or technical triage scripts every hour and generating reports to review later.
2. Dedicated Hardware (e.g., Powerhouse NVIDIA Chips)
The Value: Packing hardware like the RTX 5090 (32GB VRAM) or 6000 Pro (96GB VRAM) delivers blazing fast memory bandwidth.
The Catch: Highly dependent on hardware availability, and desktop configurations face physical VRAM ceilings compared to unified memory pools.
Best For: Active, real-time agentic execution. Running highly capable open models like Qwen 3.6 on dedicated local GPUs matches the blistering speeds users expect from cloud endpoints, making it ideal for snappy, on-demand AI agents.
3. Turnkey AI Workstations (e.g., DGX Spark class systems)
The Value: Striking a middle ground with large unified memory pools (typically around 128GB) integrated into structured architectures.
The Catch: You won't hit the absolute peak speeds of a dedicated top-tier desktop GPU cluster, but you bypass configuration headaches.
Best For: Seamless offloading. These are headless, plug-and-play boxes designed to let your primary development machine offload secondary agent tasks effortlessly without heavy manual optimization.
🫤 Dileep's Skeptical Takeaway
The assumption that the most powerful intelligence will always be universally accessible via a simple web interface is dead. The Chinese labs stand to gain most from these new developments, at least in the short term. The recent GLM 5.2 release , in retrospect, was perfectly timed. I see more people going for local deployments using GLM5.x, DeepSeek, KimiK and Qwen 3.x. The $64K question now is, will the government ban running local Chinese models within the US boundaries?
Enjoying What the AI?
Get a new edition every week, plus join the conversation on LinkedIn.
Subscribe on LinkedIn