Yes, Google is winning the AI race

What happened
Google I/O 2026 just wrapped up, and it felt less like a standard product showcase and more like a declaration of war. Google basically dumped its entire multi-year roadmap on us in a single afternoon. The clear theme this year is the transition from passive chatbots to active, autonomous partners built on a foundation of agentic workflows.
The biggest head-turners from the event include:
- Gemini Omni & Omni Flash: A groundbreaking family of multimodal models that can generate dynamic audio, image, and video outputs from any input. Gemini Omni Flash is built directly into apps like YouTube Shorts to let users create and edit videos conversationally.
- Gemini 3.5 Flash: Google's upgraded, hyper-intelligent model designed for blazing-fast performance and advanced task execution.
- "Neural Expressive" App UI: A redesigned Gemini app experience featuring vibrant colors, fluid animations, haptic feedback, and a new pill-shaped prompt bar.
- Gemini Live Integration: The Gemini Live conversational voice experience is now built seamlessly inline, meaning you don't have to switch back and forth between screens to chat.
- Agentic Capabilities: New tools for Android and workspace apps that allow Gemini to proactively automate complex tasks—like finding receipts, filing online forms, and summarizing web content.
Why this matters
For the past couple of years, the narrative has been that Google had world-class AI research but kept tripping over execution and productization. I/O 2026 changes that story. This is not just a benchmark contest. It is an ecosystem and distribution flex. By pushing Gemini 3.5, Gemini Omni, Spark, Flow, YouTube Shorts Remix, Workspace, Chrome, Android, and Search into one connected AI layer, Google is trying to make standalone AI apps feel optional, or worse, inconvenient.
The competitive dynamic has shifted:
Vs. OpenAI: OpenAI still has enormous strength in frontier reasoning, developer mindshare, and general-purpose AI workflows through GPT-5.x and its broader model ecosystem. But Google has something OpenAI does not: native placement across search, browser, phone, email, documents, video, and productivity tools. Gemini Omni inside Flow, YouTube, and the Gemini app turns creation and editing into an embedded workflow instead of a separate destination.
Vs. Anthropic: Anthropic remains extremely strong in enterprise, coding, long-context reasoning, and safety-conscious workflows, especially with Claude Sonnet 4.6 and Opus 4.7. But Claude still feels like a high-end specialized workbench. Google is trying to become the ambient AI layer surrounding the entire workday.
Vs. xAI: Grok has personality, real-time orientation, and expanding multimodal capabilities through Grok 4.3 and xAI’s image, video, voice, and coding APIs. But its center of gravity is still narrower. Google can connect prompts to Gmail, Docs, Sheets, Android, Search, Chrome, Maps, YouTube, and Workspace. That is not just a chatbot. That is distribution with teeth.
What I am testing with my Google Pro subscription:
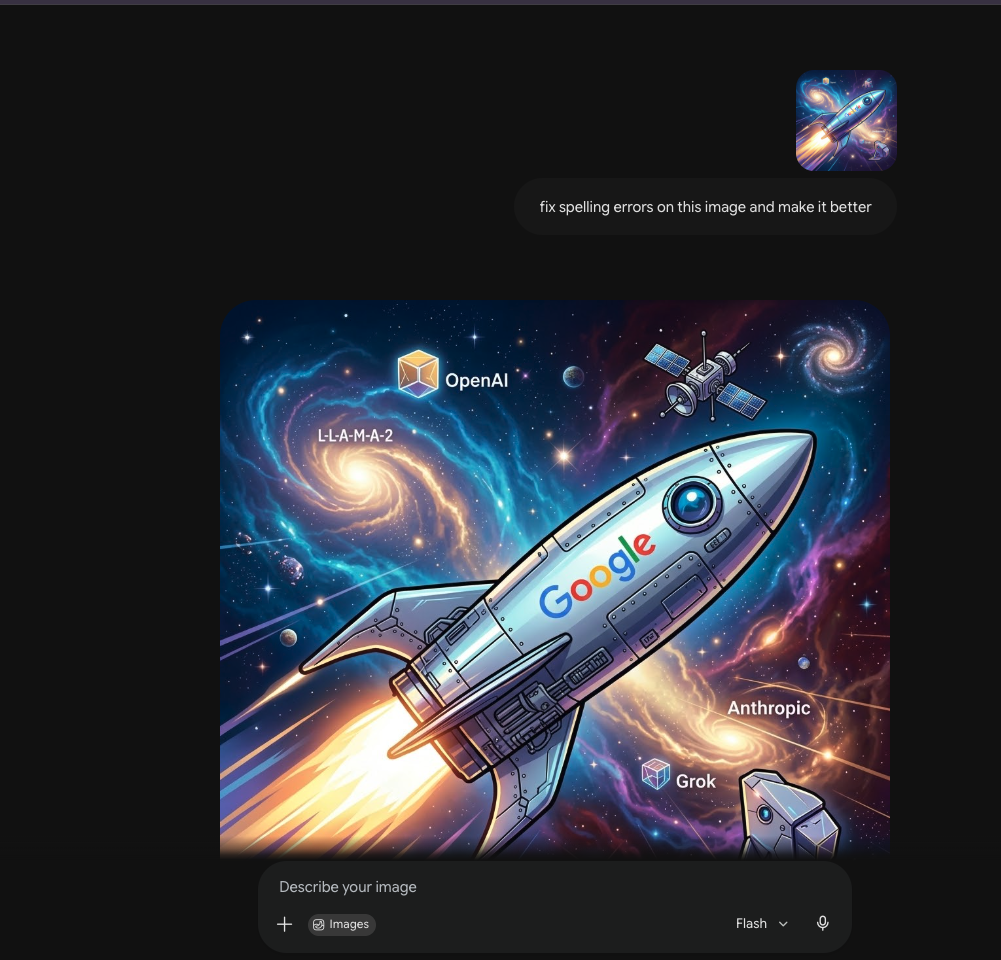
I haven't had too much time this last week to test all the features released at Google I/O. However, I did try the image to image feature in Omni and was instantly blown away. I had generated the headline image for this article in NightCafe (my go to image creator) but it introduced spelling errors - misspelling Google, Anthropic and Grok. So I gave that image to Google Omni and said "fix the spelling errors". It did EXACTLY what I asked it to do. Sounds small but it is a big deal if you have tried image generation using AI models - they inevitably introduce new errors while fixing what you ask them to fix.
Recommended by LinkedIn
 🚀 Google I/O 2025 Recap: Gemini, Veo, and the Bold…
Shubham Savaj
1 year ago
🚀 Google I/O 2025 Recap: Gemini, Veo, and the Bold…
Shubham Savaj
1 year ago
 🧠📊 Google’s Stealth Power Move in the AI War: It’s…
Atanu Dey
11 months ago
🧠📊 Google’s Stealth Power Move in the AI War: It’s…
Atanu Dey
11 months ago
 Google's top AI announcements from I/O 2026
Google
1 month ago
Google's top AI announcements from I/O 2026
Google
1 month ago
I also tried to generate a video using the new Omni model but was having spelling issues with the text-over. The quality overall is great though.
What Others Are Saying
The reaction across tech circles has been a mix of total awe and deep anxiety about pricing and platform lock in.
“Gemini Omni is a major leap in world understanding & multimodal editing! It can take photos, video & audio and build entirely new scenes. Over time it’ll be able to handle any input & any output - starting w/ video. You can even give it your own videos & iterate on your ideas - Demis Hassabis
https://x.com/demishassabis/status/2056831486251380783?s=20
I had early Gemini Omni access, it excels at instruction following in video creation. Here is what it made for the prompt: "sea otter in a pilot's uniform explains why Spirit Airlines went bankrupt to a river otter who is distracted by their laptop while they are in a hot air balloon over NYC. in the next balloon over, william shakespeare fights a robot made of pizza." - Ethan Mollick
Access to all of your apps at once is a problem - Dashia Milden
Gemini Spark Gives Google Way Too Much Access to Your Data
🫤Dileep's Skeptical Takeaway:
If the top Frontier labs were Animals, Google's approach is less like a Tiger or Cheetah and more like a Spider. It doesn't pounce upon its prey, or chase hard at 120 Mph. Instead, it plays a long game - weaving an intricate web of models, apps, editing features, 3rd party integrations, and OS embedding - to lock us in. It takes time, but it locks you in completely and before you know it, you are trapped in this web - with no escape. I must say, it is a beautiful web though.
Enjoying What the AI?
Get a new edition every week, plus join the conversation on LinkedIn.
Subscribe on LinkedIn